Reference
Concepts
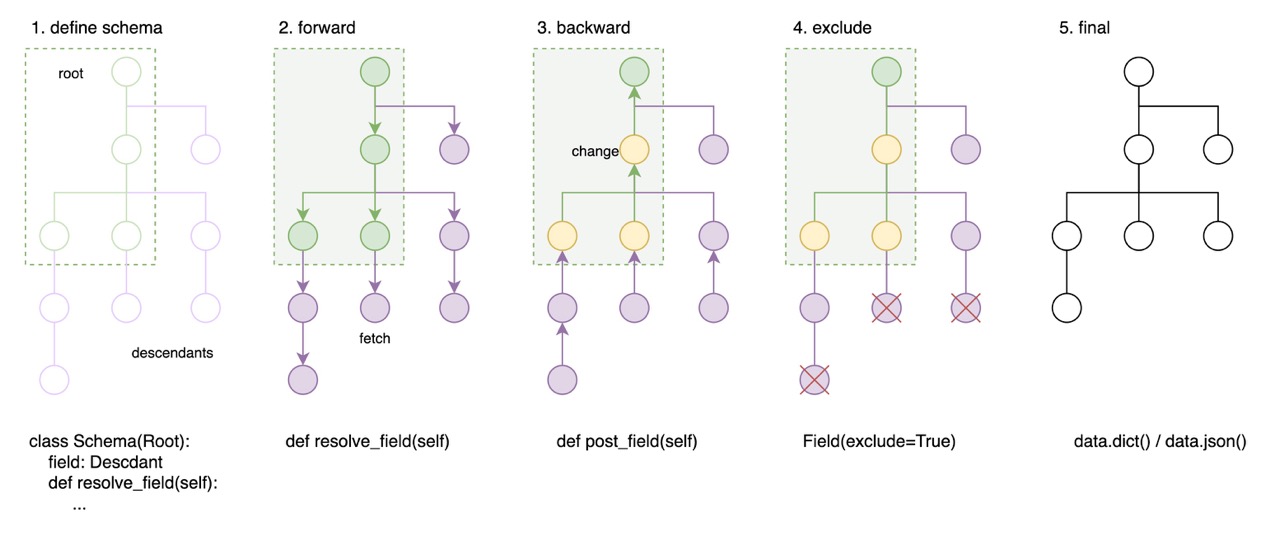
It taks several steps from root data into view data, you can manage the fetching process and tweak it after fetched.
- define schema of root data and descdants & load root data
- forward resolve all descdants data (resolve)
- backward post-process the data (post)
- tree shake the data (model_config and exclude=True)
- get the output
Resolve
Available params:
- context
- ancestor_context
- parent
- dataloaders (multiple)
resolve_field, can be async. Resolver will recursively execute resolve_field to fetch descendants
class Blog(BaseModel):
id: int
comments: list[str] = []
def resolve_comments(self):
return ['comment-1', 'comment-2']
tags: list[str] = []
async def resolve_tags(self):
await asyncio.sleep(1)
return ['tag-1', 'tag-2']
Post
Available params:
- context
- ancestor_context
- parent
- collectors (multiple)
post_field, can only be normal subroutine function.
You can modify target field after descendants are all resolved.
1) modify a resolved field,
class Blog(BaseModel):
id: int
comments: list[str] = []
def resolve_comments(self):
return ['comment-1', 'comment-2']
def post_comments(self):
return self.comments[-1:] # keep the last one
2) or modify a new field
class Blog(BaseModel):
id: int
comments: list[str] = []
def resolve_comments(self):
return ['comment-1', 'comment-2']
comment_count: int = 0
def post_comment_count(self):
return len(self.comments)
post_default_handler
post_default_handler is a special post method, it runs finally after all post_methods are done.
Available params:
- context
- ancestor_context
- parent
Method params
Context
available in: resolve, post, post_default_handler
A global (root) context, after set it in Resolver, resolve and post can read it.
class Blog(BaseModel):
id: int
comments: list[str] = []
def resolve_comments(self, context):
prefix = context['prefix']
return [f'{prefix}-{c}' for c in ['comment-1', 'comment-2']]
def post_comments(self, context):
limit = context['limit']
return self.comments[-limit:] # get last [limit] comments
blog = Blog(id=1)
blog = await Resolver(context={'prefix': 'my', 'limit': 1}).resolve(blog)
output
Ancestor context
available in: resolve, post, post_default_handler
In some scenario, descendants may need to read ancestor's field, ancestor_context can help.
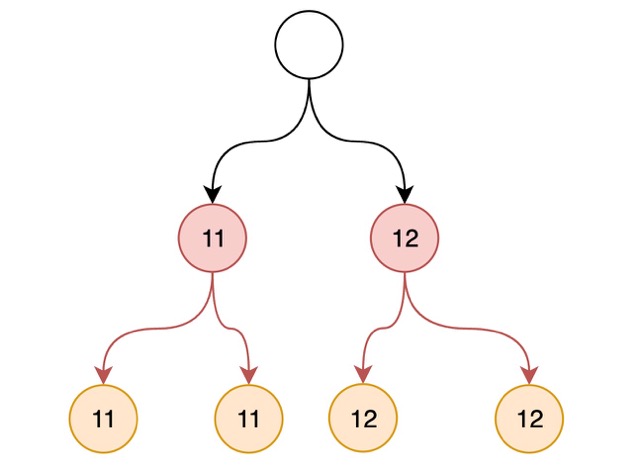
You can use __pydantic_resolve_expose__ to define the field and it's alias for descendants,
and then read it from ancestor_context, using alias as the key.
this example shows the blog title can read from it's descendant comment.
class Blog(BaseModel):
__pydantic_resolve_expose__ = {'title': 'blog_title' }
id: int
title: str
comments: list[Comment] = []
def resolve_comments(self, loader=LoaderDepend(blog_to_comments_loader)):
return loader.load(self.id)
comment_count: int = 0
def post_comment_count(self):
return len(self.comments)
class Comment(BaseModel):
id: int
content: str
def post_content(self, ancestor_context):
blog_title = ancestor_context['blog_title']
return f'[{blog_title}] - {self.content}'
{
"blogs": [
{
"id": 1,
"title": "what is pydantic-resolve",
"comments": [
{
"id": 1,
"content": "[what is pydantic-resolve] - its interesting"
},
{
"id": 2,
"content": "[what is pydantic-resolve] - i dont understand"
}
],
"comment_count": 2
},
{
"id": 2,
"title": "what is composition oriented development pattarn",
"comments": [
{
"id": 3,
"content": "[what is composition oriented development pattarn] - why? how?"
},
{
"id": 4,
"content": "[what is composition oriented development pattarn] - wow!"
}
],
"comment_count": 2
}
]
}
Parent
available in: resolve, post, post_default_handler
methods can visit parent node by reading parent. It's useful in tree-like structure.
class Tree(BaseModel):
name: str
children: List[Tree] = []
path: str = ''
def resolve_path(self, parent):
if parent is not None:
return f'{parent.path}/{self.name}'
return self.name
data = dict(name="a", children=[
dict(name="b", children=[
dict(name="c")
]),
dict(name="d", children=[
dict(name="c")
])
])
data = await Resolver().resolve(Tree(**data))
output
{
"name": "a",
"path": "a",
"children": [
{
"name": "b",
"path": "a/b",
"children": [
{
"name": "c",
"path": "a/b/c",
"children": []
}
]
},
{
"name": "d",
"path": "a/d",
"children": [
{
"name": "c",
"path": "a/d/c",
"children": []
}
]
}
]
}
Collectors
available in: post
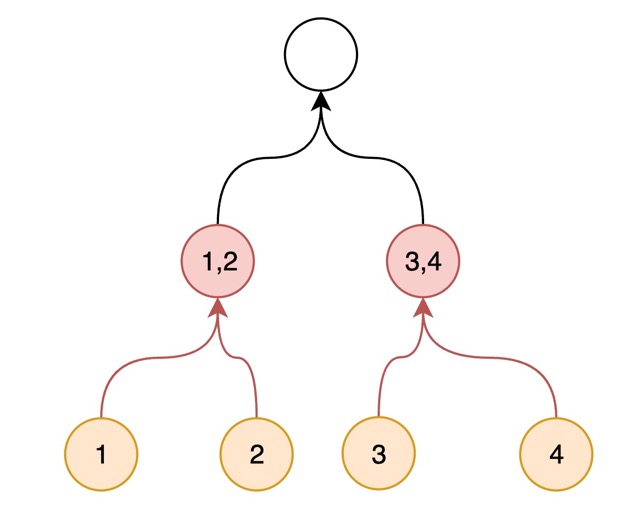
Ancestor nodes may want to collect some specific fields from it's descendants, you can use Collector and __pydantic_resolve_collect__.
It is very helpful in re-organizing your data, move data from a to b
for example, let's collect all comments into all_comments at top level:
form pydantic_resolve import Collector
class MyBlogSite(BaseModel):
blogs: list[Blog] = []
async def resolve_blogs(self):
return await get_blogs()
comment_count: int = 0
def post_comment_count(self):
return sum([b.comment_count for b in self.blogs])
all_comments: list[Comment] = []
def post_all_comments(self, collector=Collector(alias='blog_comments', flat=True)):
return collector.values()
class Blog(BaseModel):
__pydantic_resolve_expose__ = {'title': 'blog_title' }
__pydantic_resolve_collect__ = {'comments': 'blog_comments' }
id: int
title: str
comments: list[Comment] = []
def resolve_comments(self, loader=LoaderDepend(blog_to_comments_loader)):
return loader.load(self.id)
comment_count: int = 0
def post_comment_count(self):
return len(self.comments)
class Comment(BaseModel):
id: int
content: str
def post_content(self, ancestor_context):
blog_title = ancestor_context['blog_title']
return f'[{blog_title}] - {self.content}'
output of all_comments fields:
{
"other fields": ...,
"all_comments": [
{
"id": 1,
"content": "[what is pydantic-resolve] - its interesting"
},
{
"id": 2,
"content": "[what is pydantic-resolve] - i dont understand"
},
{
"id": 3,
"content": "[what is composition oriented development pattarn] - why? how?"
},
{
"id": 4,
"content": "[what is composition oriented development pattarn] - wow!"
}
]
}
values of __pydantic_resolve_collect__ must be global unique, this means it is not available in tree structure.
Usages:
-
Using multiple collectors is of course supported
-
Using
flat=Truewill callist.extendinside, use it if your source field isList[T] - You can inherit
ICollectorand define your ownCollector, for example, a counter collector.self.aliasis always required.
Dataloaders
available in: resolve
LoaderDepend is a speical dataloader manager, it also prevent type inconsistent from DataLoader or batch_load_fn.
param: can be DataLoader class or batch_load_fn function.
from pydantic_resolve import LoaderDepend
class Blog(BaseModel):
id: int
title: str
comments: list[Comment] = []
def resolve_comments(self, loader1=LoaderDepend(blog_to_comments_loader)):
return loader1.load(self.id) # return FUTURE
Multiple loaders are also supported.
from pydantic_resolve import LoaderDepend
class Blog(BaseModel):
id: int
title: str
comments: list[Comment] = []
async def resolve_comments(self,
loader1=LoaderDepend(blog_to_comments_loader),
loader2=LoaderDepend(blog_to_comments_loader2)):
v1 = await loader1.load(self.id) # list
v2 = await loader2.load(self.id) # list
return v1 + v2
DataLoader
DataLoader is a important component in pydantic-resolve, it helps fetching data level by level.
You can use the params below in Resolver, to configure your loaders.
Loader params
You are free to define Dataloader with some fields and set these fields with loader_params in Resolver
You can treat dataloader like JOIN condition, and params like Where conditions
select children from parent
# loader keys
join children on parent.id = children.pid
# loader params
where children.age < 20
class LoaderA(DataLoader):
power: int
async def batch_load_fn(self, keys: List[int]):
return [ k** self.power for k in keys ]
data = await Resolver(loader_filters={
LoaderA:{'power': 2}
}).resolve(data)
Global loader param
If Dataloaders shares some common params, it is possible to declare them by global_loader_param
class LoaderA(DataLoader):
power: int
async def batch_load_fn(self, keys: List[int]):
return [ k** self.power for k in keys ]
class LoaderB(DataLoader):
power: int
async def batch_load_fn(self, keys: List[int]):
return [ k** self.power for k in keys ]
class LoaderC(DataLoader):
power: int
async def batch_load_fn(self, keys: List[int]):
return [ k** self.power + self.add for k in keys ]
async def loader_fn_a(keys):
return [ k**2 for k in keys ]
class A(BaseModel):
val: int
a: int = 0
def resolve_a(self, loader=LoaderDepend(LoaderA)):
return loader.load(self.val)
b: int = 0
def resolve_b(self, loader=LoaderDepend(LoaderB)):
return loader.load(self.val)
c: int = 0
def resolve_c(self, loader=LoaderDepend(LoaderC)):
return loader.load(self.val)
@pytest.mark.asyncio
async def test_case_0():
data = [A(val=n) for n in range(3)]
data = await Resolver(
global_loader_filter={'power': 2},
loader_filters={LoaderC:{'add': 1}}).resolve(data)
Loader instance
You can provide loader instance by loader_instances, and prime (preload) some data before use, so that internally pydantic-resolve will use it instead of creating from loader class.
loader = SomeLoader()
loader.prime('tangkikodo', ['tom', 'jerry'])
loader.prime('john', ['mike', 'wallace'])
data = await Resolver(loader_instances={SomeLoader: loader}).resolve(data)
references: loader methods
Build list and object
helper function, use build_list for One2Many, use build_object for One2One
async def members_batch_load_fn(team_ids):
""" return members grouped by team_id """
_members = member_service.batch_query_by_team_ids(team_ids)
return build_list(_members, team_ids, lambda t: t['team_id']) # helper func
source code:
def build_list(items: Sequence[T], keys: List[V], get_pk: Callable[[T], V]) -> Iterator[List[T]]:
"""
helper function to build return list data required by aiodataloader
"""
dct: DefaultDict[V, List[T]] = defaultdict(list)
for item in items:
_key = get_pk(item)
dct[_key].append(item)
results = (dct.get(k, []) for k in keys)
return results
def build_object(items: Sequence[T], keys: List[V], get_pk: Callable[[T], V]) -> Iterator[Optional[T]]:
"""
helper function to build return object data required by aiodataloader
"""
dct: Mapping[V, T] = {}
for item in items:
_key = get_pk(item)
dct[_key] = item
results = (dct.get(k, None) for k in keys)
return results
Tips
Get information of loaders after resolved.
Visibility
better ts definitions and hide some fields
model_config
fields with default value will be converted to optional in typescript definition. add model_config decorator to avoid it.
Exclude
setting exclude=True will hide these fields, both in serilization and exporting json schema (openapi).
@model_config()
class Y(BaseModel):
id: int = 0
def resolve_id(self):
return 1
name: str = Field(exclude=True)
password: str = Field(default="", exclude=True)
def resolve_password(self):
return 'confidential'
ensure_subset(base_kls)
You can create a new pydantic class by copying the original one and keep the fields you wanted.
Decorating it with ensure_subset will validate it for you.
c is not existed in Base, exception raised.